
Sammlungssuche
Kontakt
Bildbestellung / Ordering images
Ansprechpartnerinnen:
Franziska Schilling
Claudia Zachariae
Tel.: +49 (0)30 314-23116

Workflow des DFG-Projekts DIGIPLAN
Datenvorbereitung
|
|
|
Grundlage des Digitalisierungsprojekts ist eine MuseumPlus-Datenbank zu den Beständen des Architekturmuseums, die seit 2003 im Aufbau ist und inzwischen gut 70.000 Datensätze umfasst.
Da diese Datenbank ein geschütztes, geschlossenes System ist, werden für die Digitalisierung vorgesehene Datensätze in eine offene MySQL-Produktionsdatenbank exportiert.
Struktur und Exportfelder
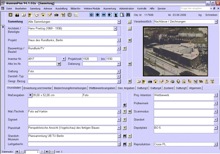

Datenbank MuseumPlus
Die interne Datenbank MuseumPlus arbeitet als relationale Datenbank auf Access-Basis mit einer Vielzahl von Tabellen, die in sehr komplexen Beziehungen zu einanderstehen. Für die Produktionsdatenbank werden lediglich Daten aus der Objektdatentabelle benötigt, die über die eindeutige Objekt-ID problemslos verknüpft und aktualisiert werden können.
Im Einzelnen werden folgende Felder exportiert:
- Objekt-ID: Die eindeutige Identifikationsnummer eines Blattes
- Inventarnummer
- Verfasser-ID
- Projekttitel
- Planinhalt
- Datierung
- Material und Technik
- Depotplatz
- Repro
|
|
|
Validierung der Daten
Noch vor dem Datenexport werden diese Felder für die anstehende Scancharge (d.h. in der Regel den Schub eines Zeichnungsschrankes) geprüft. Die Leiterin der Datenerfassung ruft dafür die zugehörigen Datensätze auf und führt folgende Prüfschritte aus:
- Konsistenz der Inventarnummer innerhalb der Inventarsystematik
- Korrekte Ansetzung des Projekttitels
- Korrekte Ansetzung der Datierungsfelder
- Korrekte Ansetzung der typologischen Felder (Bau- und Darstellungstypologie)
Mit diesem Schritt ist sichergestellt, dass diejenigen Daten, die nicht am Blatt geprüft werden können oder müssen, für die weitere Verarbeitung richtig und lesbar dargestellt sind.
|
|
|
Export in die Produktionsdatenbank

Export-Tool
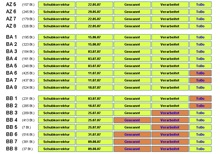
Schubübersicht der Produktionsdatenbank
Der eigentliche Datenexport erfolgt wie die meisten Prozeduren, die auf die interne Datenbank zugreifen, zunächst als VBA-gesteuerte Excel-Routine. Dazu werden die Daten aus oben genannten Feldern in ein Tabellenblatt eingelesen. Zeile um Zeile werden sie dann in eine Exportdatei geschrieben (CSV), die per FTP auf den Produktionsserver übertragen und dort, noch innerhalb der Routine, mittels PHP-Script zu einer MySQL-Tabelle verarbeitet werden.
Innerhalb der »Schubdatenbank« des Produktionsservers werden die neuen Daten jetzt als zu verarbeitender Schub dargestellt, dessen einzelne Datensätze beim Ausheben kontrolliert werden müsen und gegebenfalls geändert werden können.
|
|
|